05-1 결정 트리
05-1 결정 트리
decision tree
🌟 결정 트리는 표준화 전처리 과정이 필요하지 않음! 🌟
import pandas as pd
wine = pd.read_csv('https://bit.ly/wine_csv_data')
처음 샘플 5개 출력
- 화이트 와인 -> 1, 레드 와인 -> 0
–> 따라서, 전체 와인 데이터에서 양성 클래스인 화이트 와인 선별
# 풀러온 데이터 출력 --> 처음 5개 샘플 출력
wine.head()
실행결과)
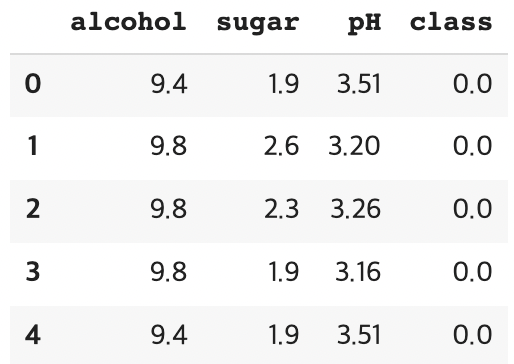
wine.info() # 데이터프레임의 각 열의 데이터 타입과 누란된 데이터 체크
실행결과)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6497 entries, 0 to 6496
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 alcohol 6497 non-null float64
1 sugar 6497 non-null float64
2 pH 6497 non-null float64
3 class 6497 non-null float64
dtypes: float64(4)
memory usage: 203.2 KB
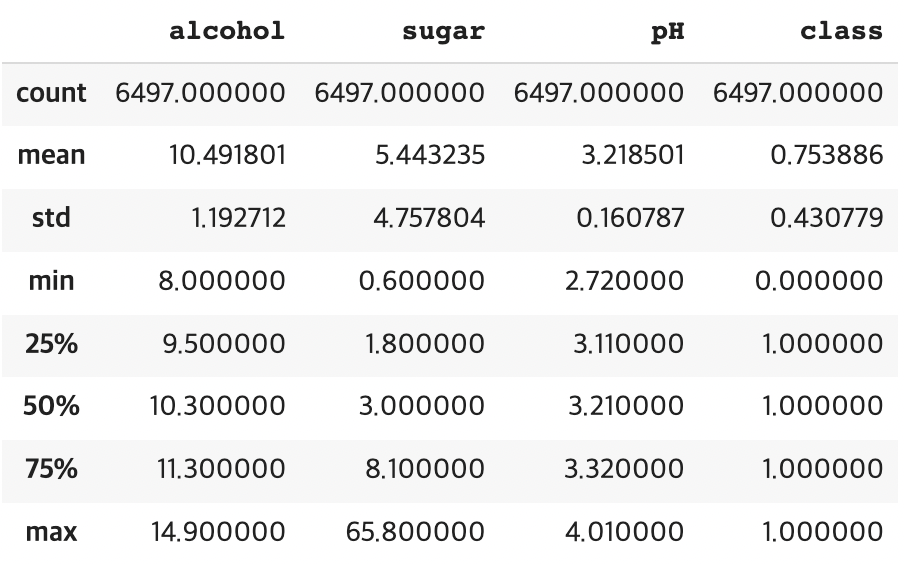
describe()
- 알코올 도수와 당도, pH 값의 스케일이 다름!! –> 특성의 표준화 필요
wine.describe() # 열에 대한 간단한 통계 출력 --> 최소, 최대, 평균값 등
실행결과)
# 훈련 세트와 테스트 세트로 분할 및 판다스 데이터프레임 -> 넘파이 배열 변환
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
from sklearn.model_selection import train_test_split
# 샘플 개수가 충분히 많다면 0.2->20%도 충분!
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)
print(train_input.shape, test_input.shape)
실행결과)
(5197, 3) (1300, 3)
특성 데이터셋 전처리 작업
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
로지스틱 회귀 모델 훈련
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target))
print(lr.score(test_scaled, test_target))
# 점수가 둘 다 낮음! 과소적합
실행결과)
0.7808350971714451
0.7776923076923077
print(lr.coef_, lr.intercept_) # 로지스틱 회귀 모델이 학습한 계수와 절편
실행결과)
[[ 0.51270274 1.6733911 -0.68767781]] [1.81777902]
DecisionTreeClassifier 결정 트리 모델 훈련
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_target))
실행결과)
0.996921300750433
0.8592307692307692
plot_tree() 를 이용한 결정 트리 생성
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(10, 7))
plot_tree(dt)
plt.show()
실행결과)

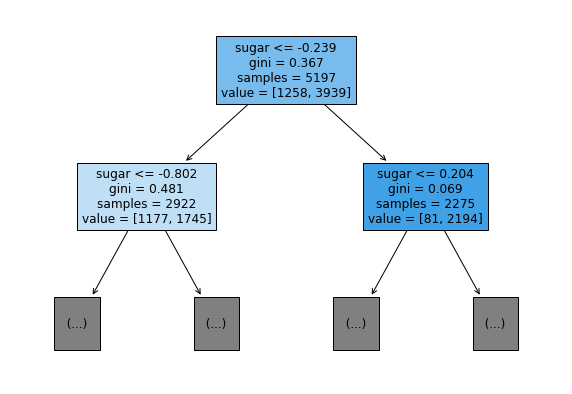
트리의 깊이를 제한한 뒤 출력
- max_depth=1 –> 루트 노드를 제외하고 노드 1개 추가
plt.figure(figsize=(10, 7))
# filled=True --> 클래스마다 색 부여, 특정 클래스의 비율이 높아지면 점점 진한 색으로 표시
plot_tree(dt, max_depth=1, filled=True, feature_names=['alcohol',
'sugar', 'pH'])
plt.show()
실행결과)
결정 트리 모델은 특성 전처리 과정이 필요 없으므로! 전처리 과정 이전의 데이터를 이용하여 모델 훈련
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_input, train_target)
print(dt.score(train_input, train_target))
print(dt.score(test_input, test_target))
실행결과)
0.8454877814123533
0.8415384615384616
plt.figure(figsize=(20, 15))
plot_tree(dt, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()
실행결과)
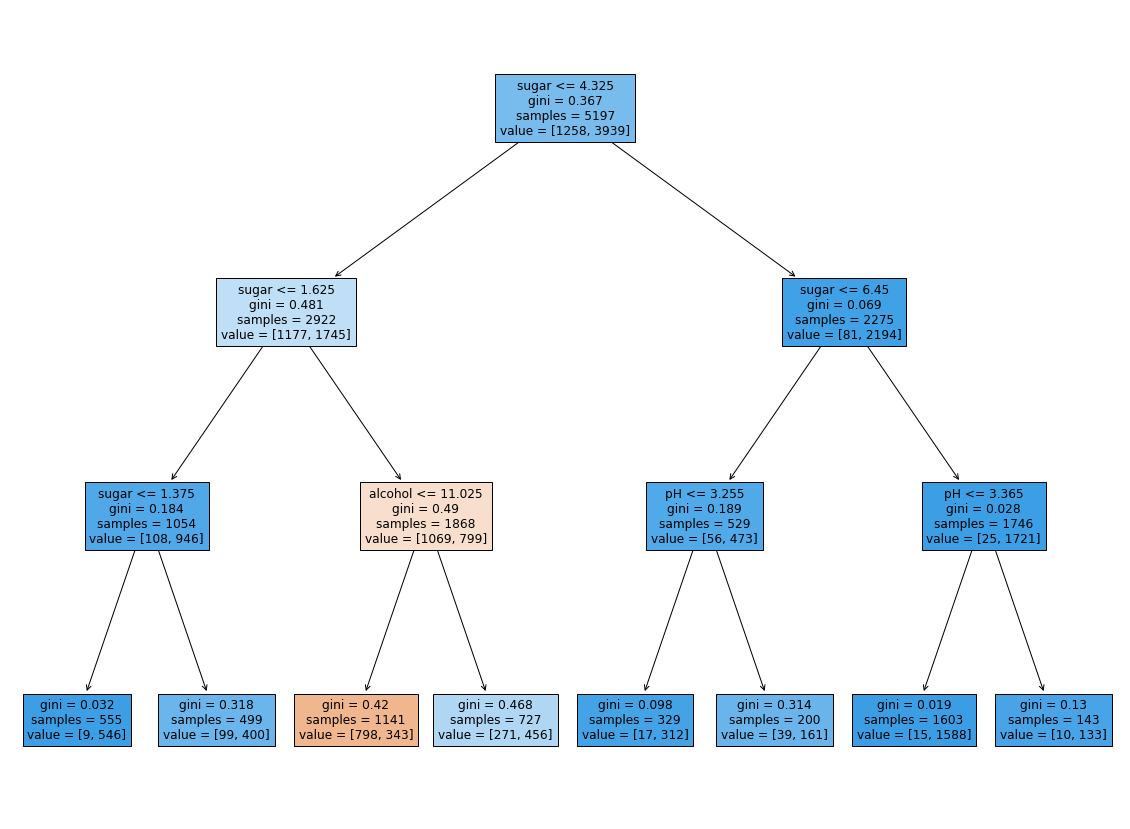
특성마다 결정 트리 모델이 중요하다고 생각하는 특성이 존재함!
print(dt.feature_importances_) # 특성 중요도 출력 --> 알코올 도수, 당도, pH 순서임
실행결과)
[0.12345626 0.86862934 0.0079144 ]
댓글남기기